Category: 🧩 Misc
Writeup Author: towfiq-rakin aka rayquaza
Team: GasMask
Challange Description
I was trying to listen to my friend’s new song, but it seems to get all scrambled up after the first second. Can you unscrambled it for me?
NOTE: The flag is fully lowercase!
Attached file: choppy.wav
Initial observations
What a messy audio! That sounded like a scrambled random noise. I could have done nothing by hearing the audio other than straining my ears! However, visualizing the audio via spectrogram may have given me some hints as the author mentioned about scrambled song. As a result I fired up ocenaudio (or you may use any audio editor) and got this:
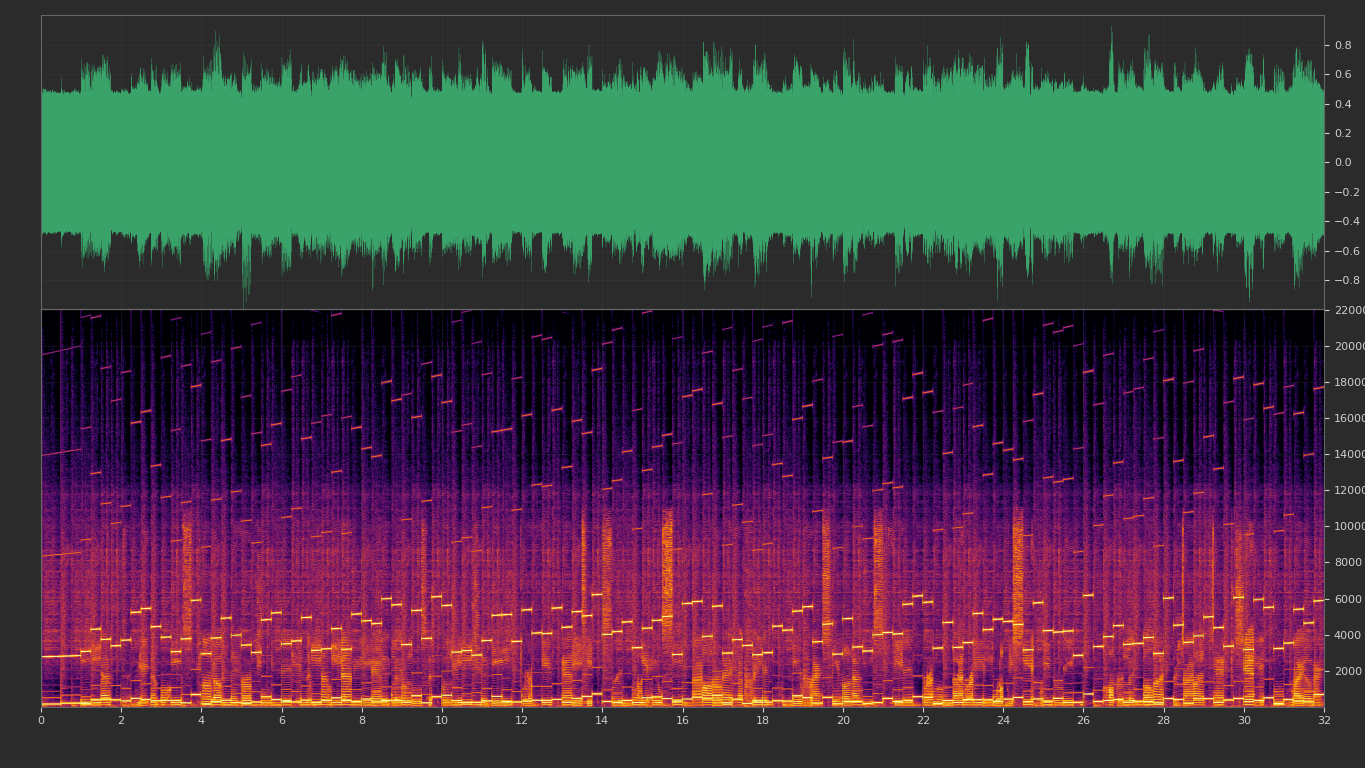
We can clearly see this is in fact a discrete signal which made our target clear: we have to sort those chunks in such way so that the signal in continuous again.
Why 0.25 second chunks?
After a quick count, I found that there are exactly 4 chunks in each second (0.25s each). As the song is exactly 32 seconds and the first second is intact, that means there are scrambled chunks.
What did not work
I first tried direct audio-edge matching:
- compare the end of one chunk with the start of another
- use short spectrogram features near each boundary
- greedily chain chunks or use Hungarian assignment on those boundary costs
This got close, but not clean enough. The audio improved, yet there were still too many bad joins.
The approach that worked
The successful method treated the problem like a 1D jigsaw puzzle on spectrogram strips
-
Preserve the known-good first second
-
Split the scrambled region into 124 chunks
-
Convert each chunk into a spectrogram strip
-
Score how well chunk
ican be followed by chunkj
For each pair of chunks, I compared:- the right edge of chunk
i - the left edge of chunk
j
The seam cost used three terms:
- direct edge similarity
- one-step linear extrapolation from the end of chunk
i - edge-gradient continuity
In code form, the cost looked like this:
direct = ((left - right_i) ** 2).mean(...) extrap = ((left_first_col - predicted_next_col_i) ** 2).mean(...) grad = ((left_grad - right_edge_grad_i) ** 2).mean(...) cost = 0.7 * direct + 0.8 * extrap + 0.5 * gradThis worked better than raw waveform matching because the scrambled signal had clear spectrogram structure even when the time-domain samples were noisy.
- the right edge of chunk
-
Anchor the chain using the intact first second
To find the first scrambled chunk, I took the last 0.25 seconds of the intact first second and computed the same kind of seam cost against every chunk start. The chunk with the smallest anchor cost became the first chunk after the intact intro. -
Recover the ordering with assignment
I built a full124 x 124cost matrix, then solved a minimum-cost one-successor/one-predecessor assignment with the Hungarian algorithm.
That produced a permutation where each chunk points to its best next chunk under the global cost.
With the spectrogram-strip cost, this assignment became a single 124-chunk cycle, which was the strongest sign the model was right.
Starting from the anchored chunk, I simply walked that cycle to recover the full order. -
Rebuild the output
The final file was:- original first second
- chunk 99
- chunk 39
- chunk 67
- …
- continue following the cycle until all 124 chunks are used
That concatenation was written out as
spectrocycle_025.wav.
Why I trusted spectrocycle_025.wav?
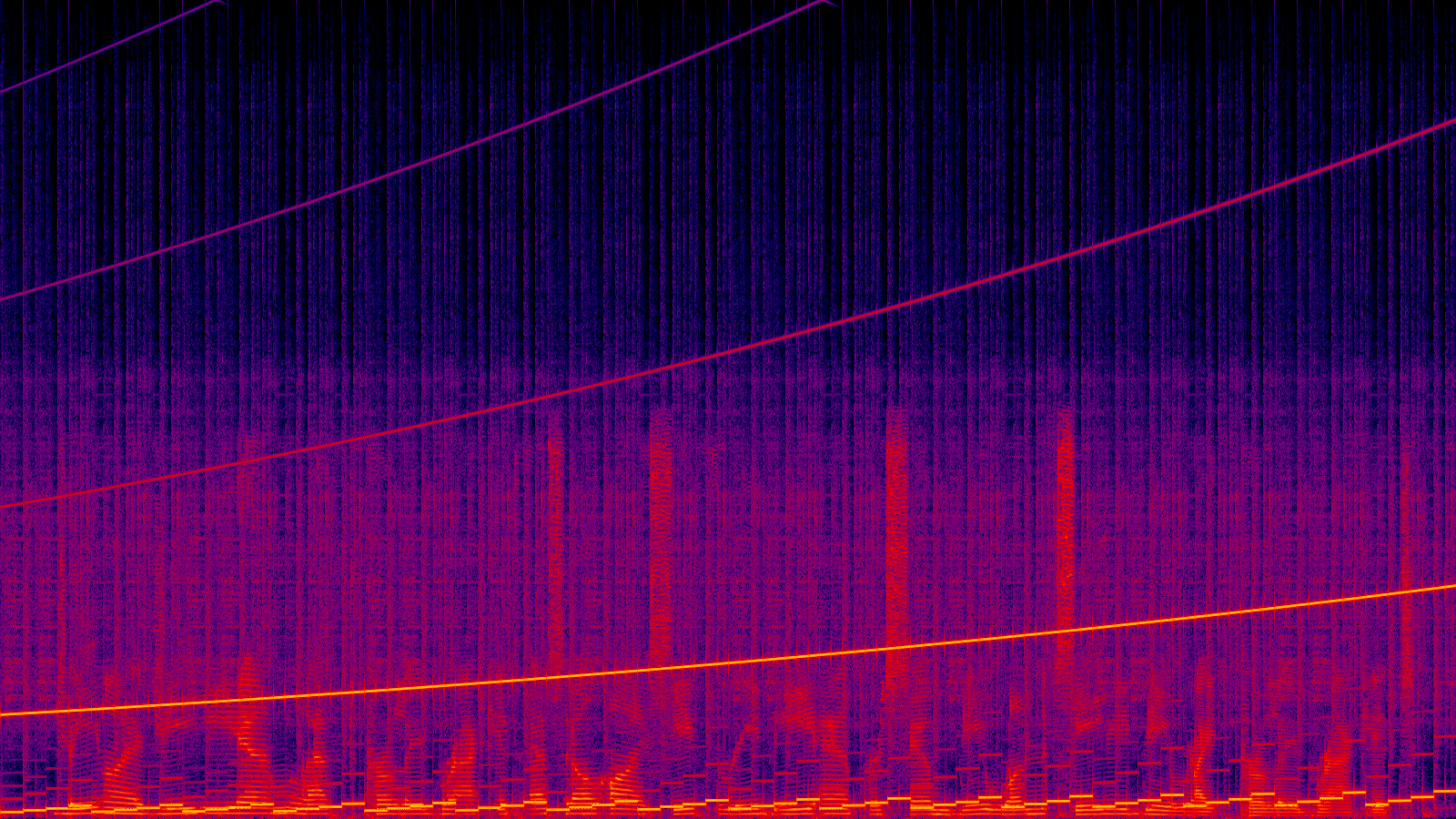
Now, the large discontinuities from the original scrambled file were mostly gone showing a continuous signal.
Most importantly, the reconstructed file became intelligible enough that I could hear spoken letters through the noise. That was the confirmation that the ordering was correct.
Minimal reconstruction sketch
This is the core structure of the script that produced spectrocycle_025.wav:
sr, x = wavfile.read("choppy.wav")
first_second = x[:sr]
scrambled = x[sr:]
chunk_len = int(0.25 * sr)
chunks = scrambled.reshape(124, chunk_len)
# build spectrogram strips for each chunk
strips = [log_spectrogram(chunk) for chunk in chunks]
# build pairwise seam cost matrix
D[i, j] = seam_cost(right_edge(strips[i]), left_edge(strips[j]))
# anchor using the last 0.25s of the intact first second
start = argmin(anchor_cost(last_quarter_of_first_second, strips[j]))
# global successor assignment
rows, cols = linear_sum_assignment(D)
perm = cols
# walk the single cycle from the anchored start
order = [start]
cur = start
while True:
nxt = perm[cur]
if nxt == start:
break
order.append(nxt)
cur = nxt
y = np.concatenate([first_second, chunks[order].reshape(-1)])
wavfile.write("spectrocycle_025.wav", sr, y)Wait!!!
Wait! We didn’t got the flag yet. Though I can hear letters from the audio like g ,i, g ,e, m, left curly bracket; due to extreme high pitch noise and instrumental sound, recovering the entire flag still seemed impossible.
I and our team used some noise remover websites and tools multiple time and got a cleaner version which helped us to recover some extra letters. After extensive joint effort, we recovered:
The End
From here, we understood that there are two words separated by a &. But brute forcing those 4 letters was kinda impossible, so I started wondering what valid words can we get by filling up those blanks. Following that, I used Crossword Solver to reconstruct the words.
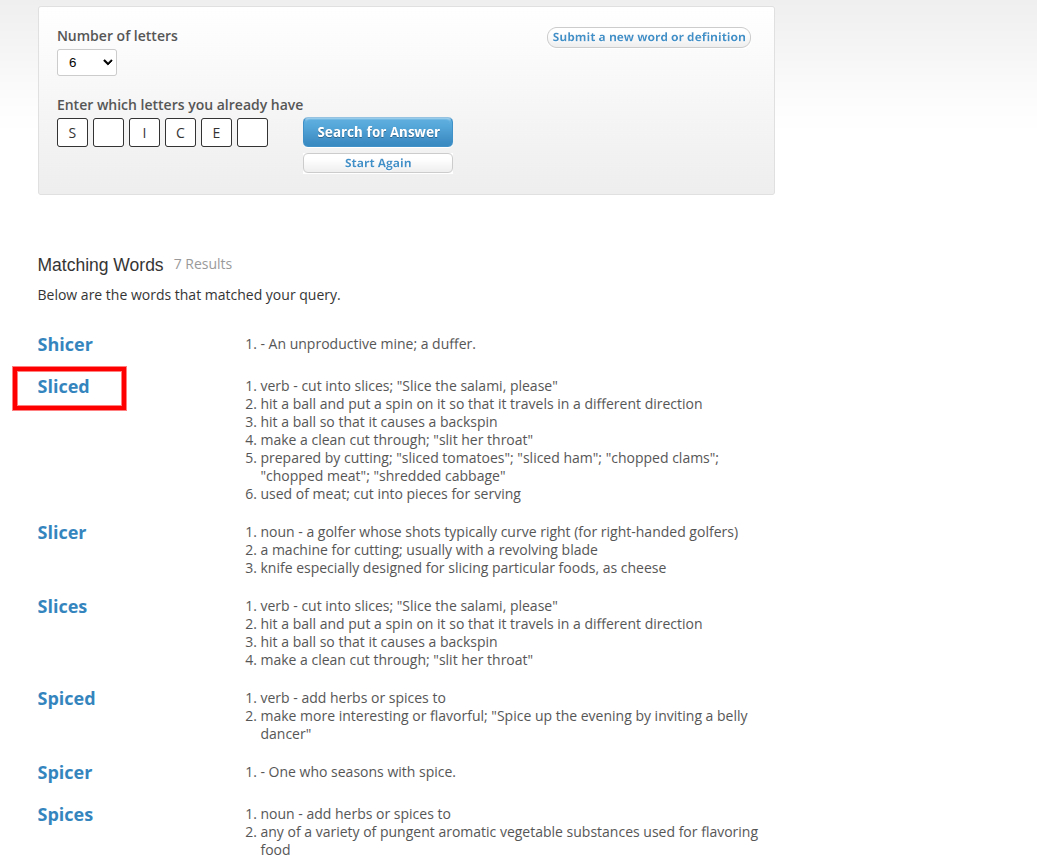
My eyes immediately hit the word sliced, which in fact aligns with our challenge as the song was sliced into multiple pieces. We noted that as a potential solution.
Finding the second word wasn’t that tough. There are only 8 possible meaningful words for dic_ _ and diced aligns perfectly with sliced and that challenge.
Meaning, the song was sliced into multiple pieces and then shuffled like a dice.
Flag: gigem{slic3d&d1ced}